外网SQL
1 | SELECT |
执行计划:
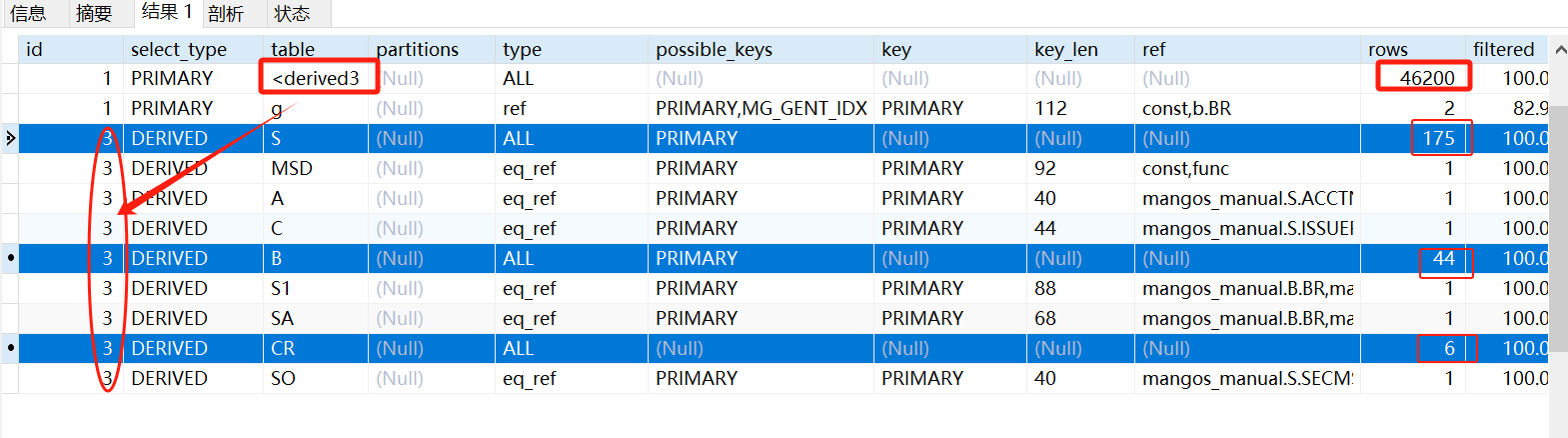
内网的执行计划,驱动表等执行计划发生变化,因为内外网的数据库数据不一样:
:::success
rows为SQL执行器预估将要扫描的行数,更标准的是通过查询条件获取的最终记录行数:
而filtered表示通过查询条件获取的最终记录行数占通过type字段指明的搜索方式搜索出来的记录行数的百分比
所以可以看到经过筛选条件 = 1条数的,不管type是什么类型,filtered必然100%
:::
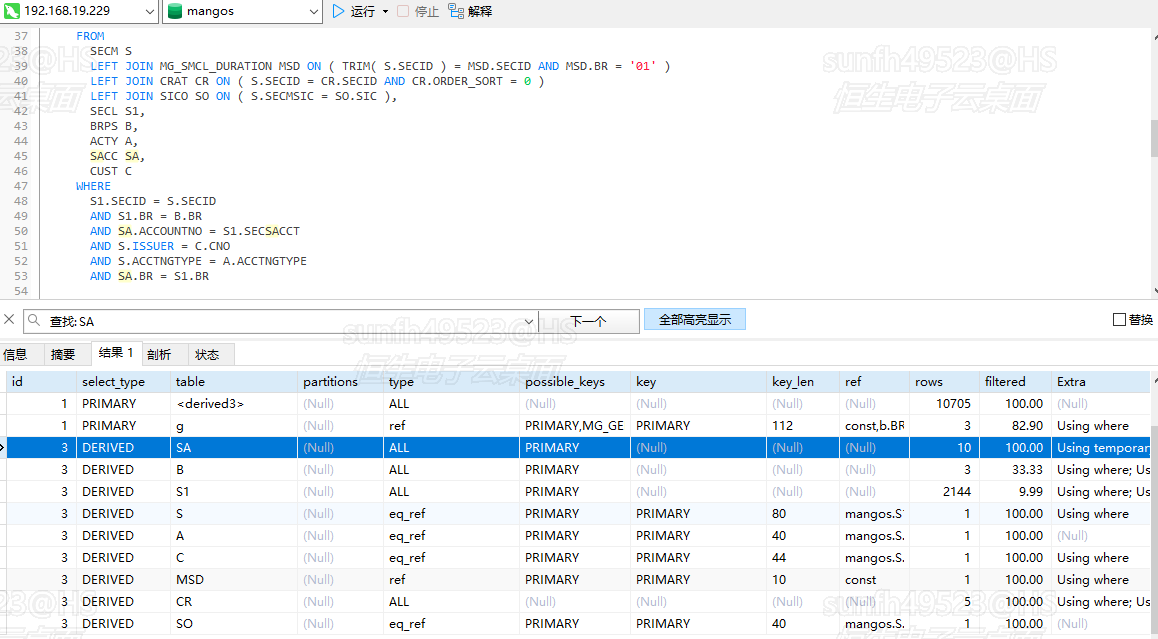
可以得出一个结论,第一个查询表也就是驱动表,因为不会生效关联条件的索引,所以一定是all的全表扫描(先忽略where或者o单字段查找的情况),之所以https://www.jianshu.com/p/a0673621c94f中显示a表走了index,这里也是where的**employee_id**条件加上了索引,而不是a.c的
a.c一定不走索引,为什么?因为表关联的算法是NOOP,最外层的驱动表循环一定是全表(不加where条件(不走where字段的索引)的时候),
但是还存在一个问题,内网的SA表,where条件的其字段accno和br是联合索引,为什么where的索引都没生效呢?
:::success
前置结论:where中都有条件的话,小表是驱动表,那么这里就是SA最小
:::
将内网的SQL修改为以下形式,完全等效,注意where表关联的方式对应的是 inner join,虽然这个SQL效率相同,但是还是建议使用join方式而不使用where产生临时大表:
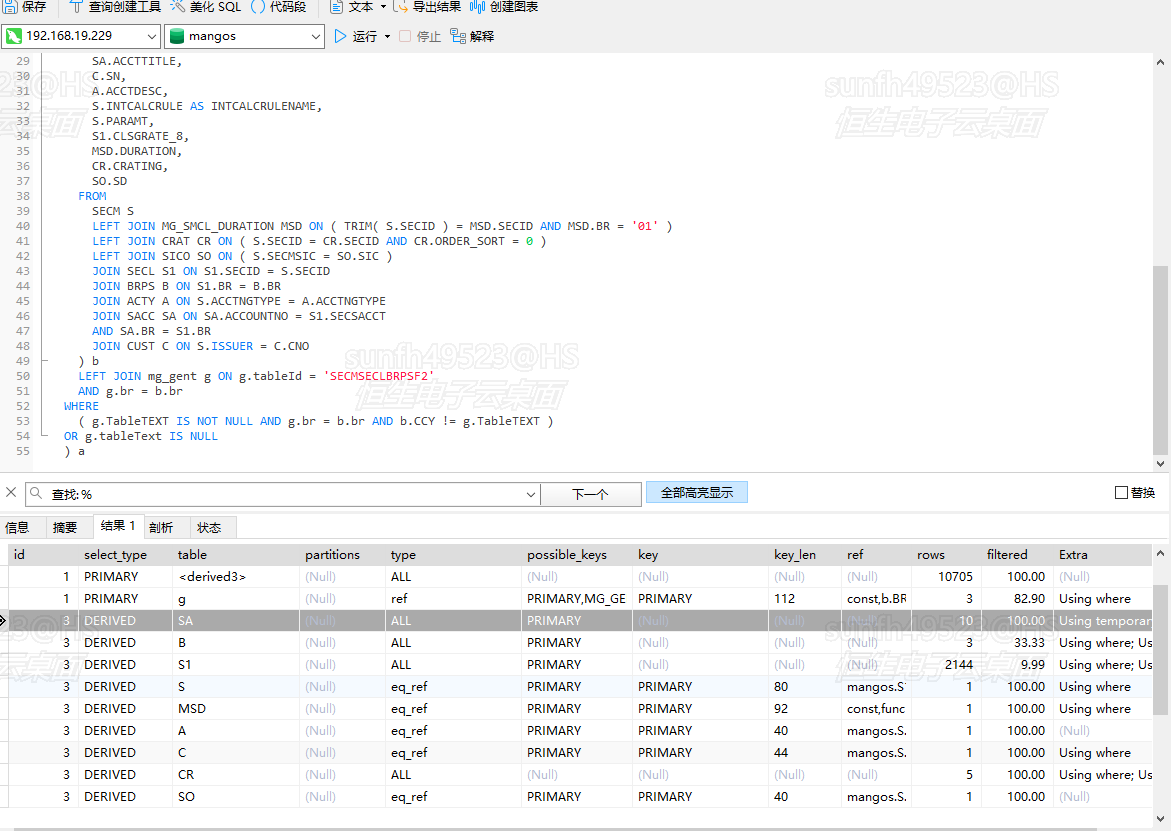
所以得出了一个结论(自己理解的):
where中写驱动表的关联条件,即使其写在where中但是其是驱动表,所以此时的where相当于写在join中(可能是优化),并不是相当于索引生效,但是推测如果where再加入一个 sa.br = ‘01’,这个时候就不是ALL了
验证:
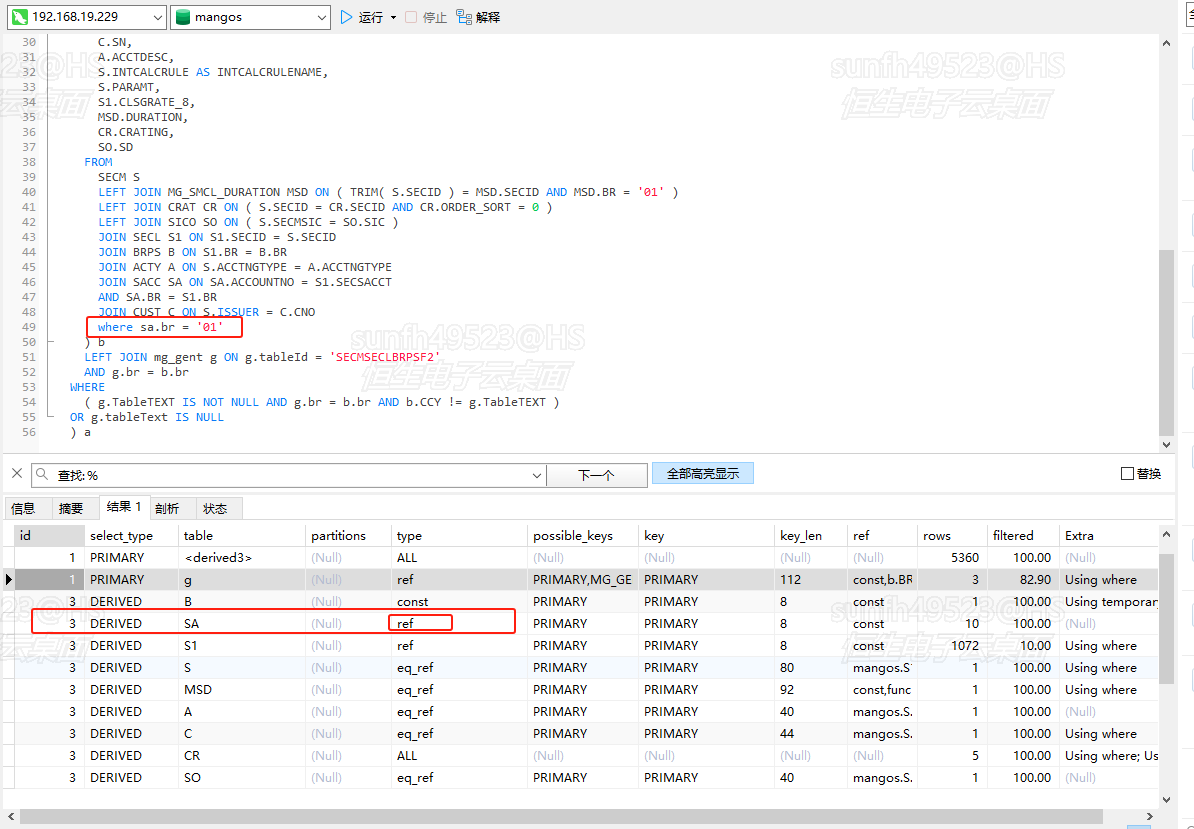
结论成立!
加在join上: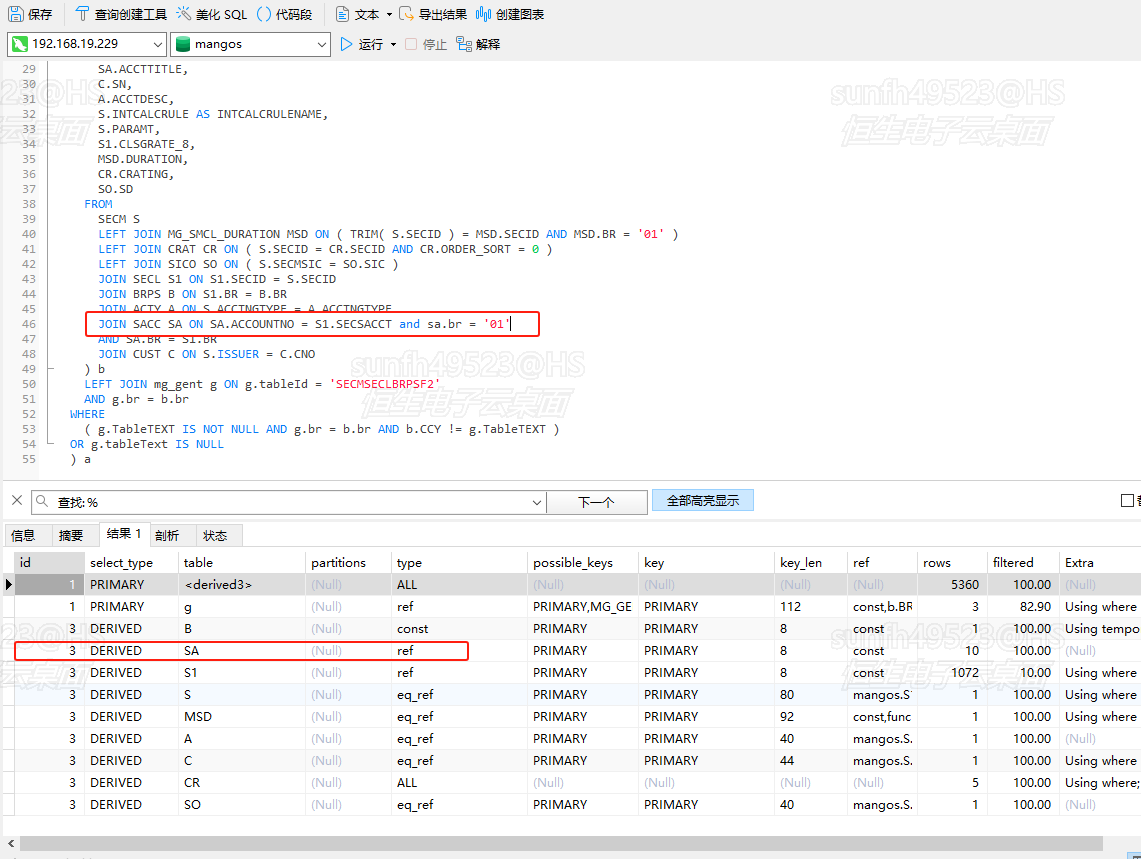
发现结论居然还能成立,说明驱动表走不走索引取决于条件是笛卡尔积条件还是单字段条件,和where和on无关
注意谁是驱动表是和where/on 的位置有关的
谁是驱动表和驱动表是不是走索引优化是两个问题!!!
案例:
trim移位,为什么S变为驱动表?
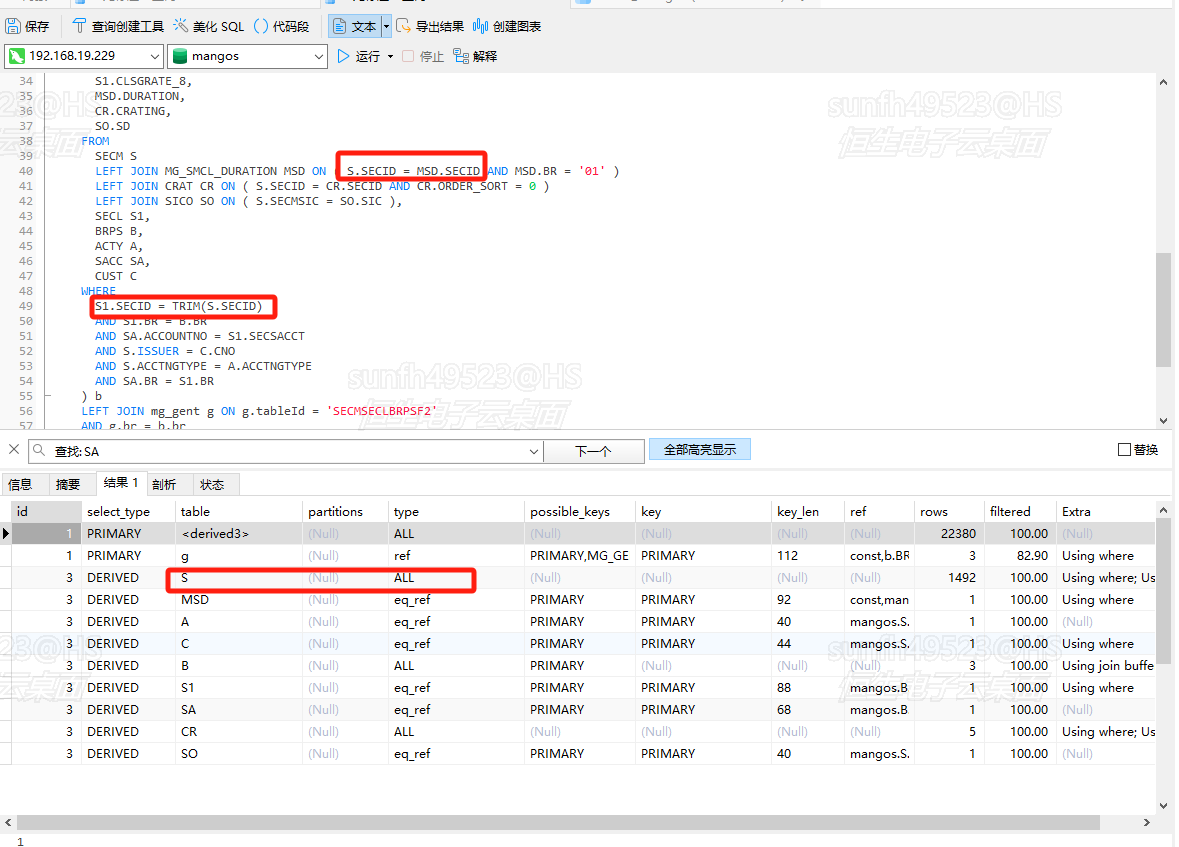
将S改为驱动表,因为SECID这个主键都是“表关联条件”,所以一定是ALL,这里只需要关注第一和第二个红框就可以了,因为issuer和acctype不是主键
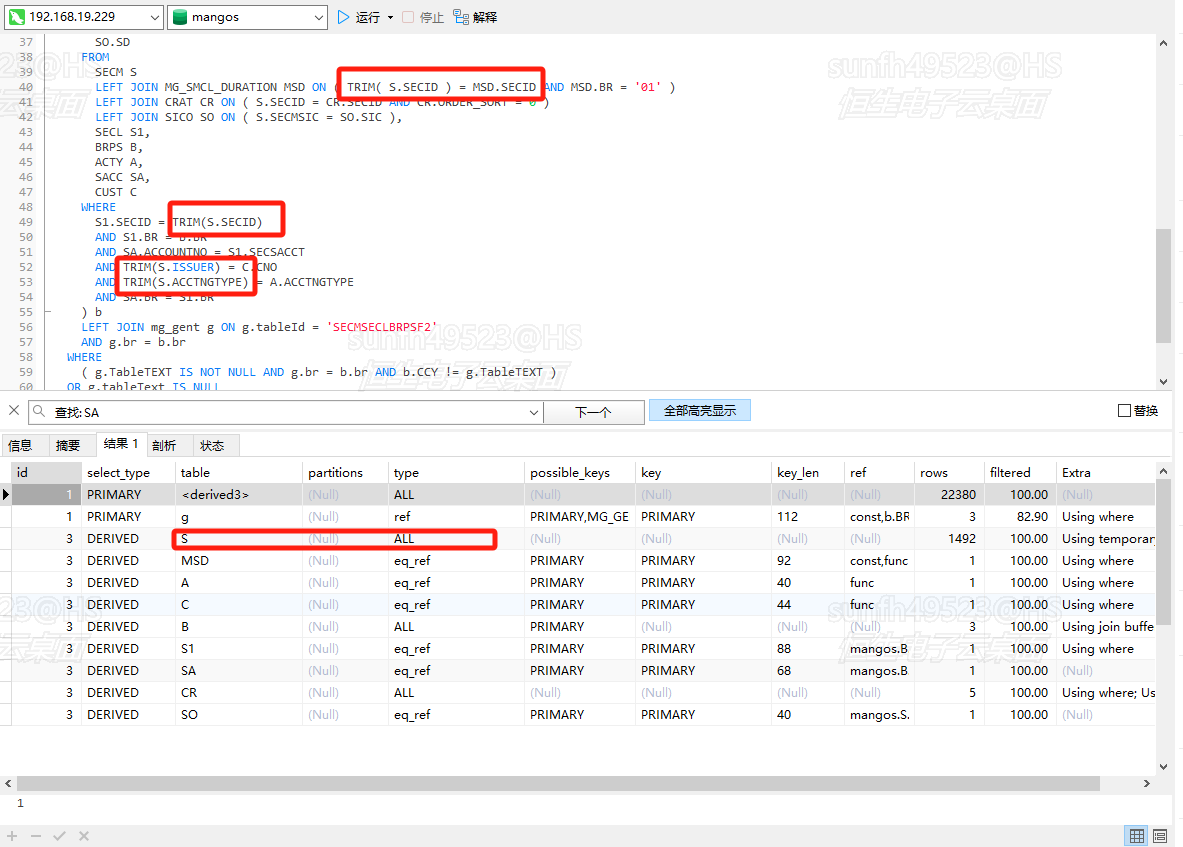
将S改为非驱动表,可以得出下图红框关联条件也就是S1和S关联条件决定了S是否是驱动表,猜测加入trim使得执行器将S当作了小表(发现上面的trim不起影响)
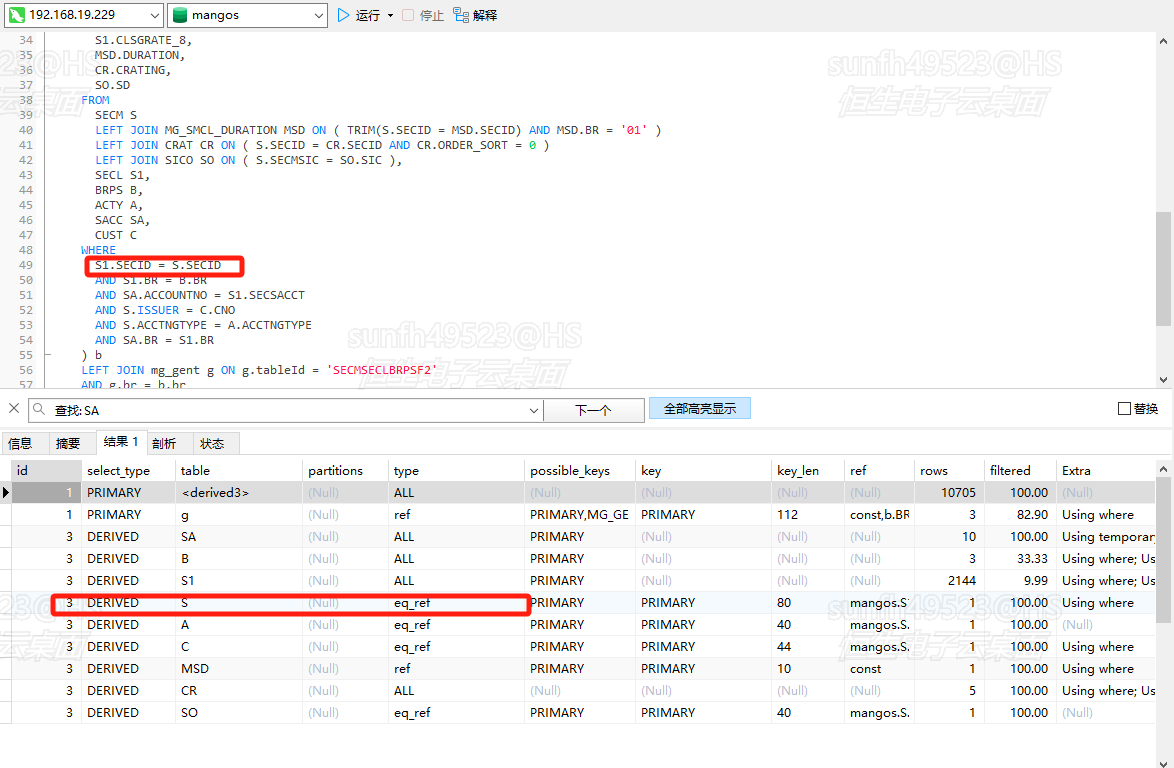
所以看一个join优化某表索引是否生效,先看是不是把某表当作驱动表了,驱动表即使显示走了索引,那也只是筛选条件走了索引,关联条件我们强调过是一定不走索引的,因为在最外层
即使一个表走了索引,也不确定走的是哪一列,我们只能尽可能的保证让筛选条件(不管where还是on)和非驱动表的关联条件走索引
但是由于数据库数据不同,执行器决定将哪一个表作驱动表也不一定,所以在A库将b非驱动表加了索引,换 一个环境导致b成驱动表了,但是a没建索引,那么性能就比前,所以只能尽可能保证速度快。
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !