最近重新深入多线程中的细节问题进行了深入,在死锁、终止线程、Guava、线程池以及队列又有了深入的思考。
在线程的生命周期中,我们常说的其实就五个状态,其中阻塞态包括了sleep以及wait都可以当作处于阻塞态,当然两种方法产生的效果当然是不同的
对阻塞态即blocked状态进行细分:
等待阻塞:wait()方法调用,这种属于主动调用
同步阻塞:线程在获取synchronized锁时没拿到,会进入同步阻塞状态
其他阻塞:使用sleep休眠或者join等待其他线程的执行、或者发出了IO请求
等待阻塞需要重新获取锁,同步阻塞是一种等待状态,而sleep不会释放锁,而join从原来上来看使用了wait方法,所以会释放锁,等待调用的线程对象执行完,currentThread才会继续执行
而yield和阻塞状态无关,会直接进入到就绪状态等待CPU时间片的分配
join释放锁和可能产生的死锁问题详解
产生死锁示例:
1 | public class ThreadJoinTestLock { |
为什么会产生死锁?
因为obj已经被主线程锁了,另一个线程再去sync,当然获取不到了
如果将ThreadJoinTestLock的锁对象修改为线程对象mythread:
1 | synchronized (mythread) { |
这样会把锁的线程对象进行释放,当然不会产生死锁了,重点在于搞清楚锁的到底是谁
PS:但是join释放锁和wait释放锁是有区别的,wait需要重新抢占对象的锁,但是join等待调用线程执行完之后就可以继续执行了,原因就是join释放的不是调用的Object对象的锁,synchronized锁的一般是Object对象,而join源码中用的是this.wait,而join只能线程对象去调,所以释放的是thread1的锁
如下:
1 | synchronized(obj){ |
第一个为什么不释放锁,因为锁的是Object对象,thread对象调的join,没得释放
第二个锁的是thread,所以会释放,所以另外的线程可以在thread.join时拿到锁,不会死锁
Thread如何终止线程
1.正常情况下,当然等线程的run执行体执行完之后线程会自动终止
2.stop()方法
是一个不安全的方法,并且在新版本JDK中被deprecated
1 | 为什么弃用stop: |
PS:线程的管理方法
start():启动线程并执行相应的run()方法
stop():执行线程体
resume():用于继续执行已经挂起的线程
suspend():用于挂起一个线程,当然是到一个安全点在挂起
destory():用于销毁线程组及其所有子组。线程组必须为空,表示该线程组中的所有线程此后都已停止。,被弃用了
3.比较安全的线程停止方式:中断,interrupt(),是非静态方法
属于主动式中断,也就是会设置一个标志位,线程会不断轮询标志位,当标志位为真时,会在最近的一个安全点挂起线程。
可以先获取当前线程再调:
1 | Thread.currentThread().interrupt() |
调用interrput会抛出InterruptedException异常,要进行捕获或抛出
需要明确的一点的是:interrupt() 方法并不像在 for 循环语句中使用 break 语句那样干脆,马上就停止循环。调用 interrupt() 方法仅仅是在当前线程中打一个停止的标记,并不是真的停止线程。
线程中断并不会立即终止线程,而是通知目标线程,有人希望你终止。至于目标线程收到通知后会如何处理,则完全由目标线程自行决定。这一点很重要,如果中断后,线程立即无条件退出,那么我们又会遇到 stop() 方法的老问题。所以可以理解成线程会执行到一个安全点再停止。
在项目中遇到了这个问题,下面是代码中的注释:
2
thread.stop();我是这样理解的,因为测试任务已经执行完了,这里使用了readLine来读取执行结果,如果出现设备未连接就调用这个方法的情况(因该方法传入的参数是InputStream,然后用readBuffer读的),导致inputstream阻塞,所以也没有将inputstream关闭,直接把测试线程中断了(在设备未连接的情况线程没有必要继续执行)
为什么不用interrupt()?
原因是:interrupt会中断阻塞抛一个异常并设置标志位,而不是直接中断线程。如果线程没阻塞就会继续执行,阻塞了就会被打断,接着继续执行线程,不能达到中断任务的目的。所以说我们在使用interrupt时一般是和一个标志位进行配合:
也可以用for循环来控制线程的执行,用for循环的继续执行条件来完成终止操作。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
() ->
{
Thread thread = Thread.currentThread();
for (int i = 0; i < 5 && !thread.isInterrupted(); i++) {
LOGGER.info("线程" + thread.getName() + "i=" + i + "isInterrupted=" + thread.isInterrupted());
;
if (i == 2) {
thread.interrupt();
}
}
LOGGER.info("线程" + thread.getName() + "停止运行" + "isInterrupted=" + thread.isInterrupted());
}
).start();
为什么推荐用自己的定义的全局flag去判断?
原因是自己定义的范围更广,而判断线程自带的标志位比较麻烦要调方法,flag也可以应用到中断阻塞线程上,如main线程调用thread01.interrupt(),而thread01的run中一直是sleep的,sleep是不能判断falg的,thread01依靠判断标志位来决定是不是停止自己,所以掉了interrupt之后,抛了Exception就会强行中断sleep,所以会到thread01的catch中判断标志位,然后标志位是true,就可以放心中断自己了。可以用isInterrupted去判断是不是被中断了,原理是通过检查是否有标志位的设置,如果自己不设置标志位的话,就用isInterrupted判断标志位是不是true,注意这个interrupt()第一次执行会把标志位变为true,再次调用的话就变成false了。
守护线程
守护线程是如果系统中只要有一个非守护线程在运行,那么守护线程就不会结束,所以在Java中将用户线程设置为守护线程之后,只有当main主线程结束之后,守护线程才会结束
1 | thread01.setdaemon(true); |
关于Guava中的多线程
除了语言本身与JDK在不断的进化,第三方库、框架也同样是日新月异。Guava正是这样一个现代的库,它简单易用,对Java语言是一个非常好的补充,原因是原本Java自身的缺陷以及使用诟病。
当然Apache也算是第三方的类库,就像python中的很多第三方一样。
比如初始化集合
1 | //JDK |
在多线程线程池中:池中的多个线程命名都是Thread-01等等由系统分批,如果我们有多个任务,每个任务有各自执行任务的线程池,那么在任务执行打印日志时,我们是无法分清楚执行线程是属于哪一个池的,当然在执行单个线程的时候,我们可以使用Thread.setName来指定线程的名称,但是在Java中没有提供一个可供修改线程中线程命名的方式。
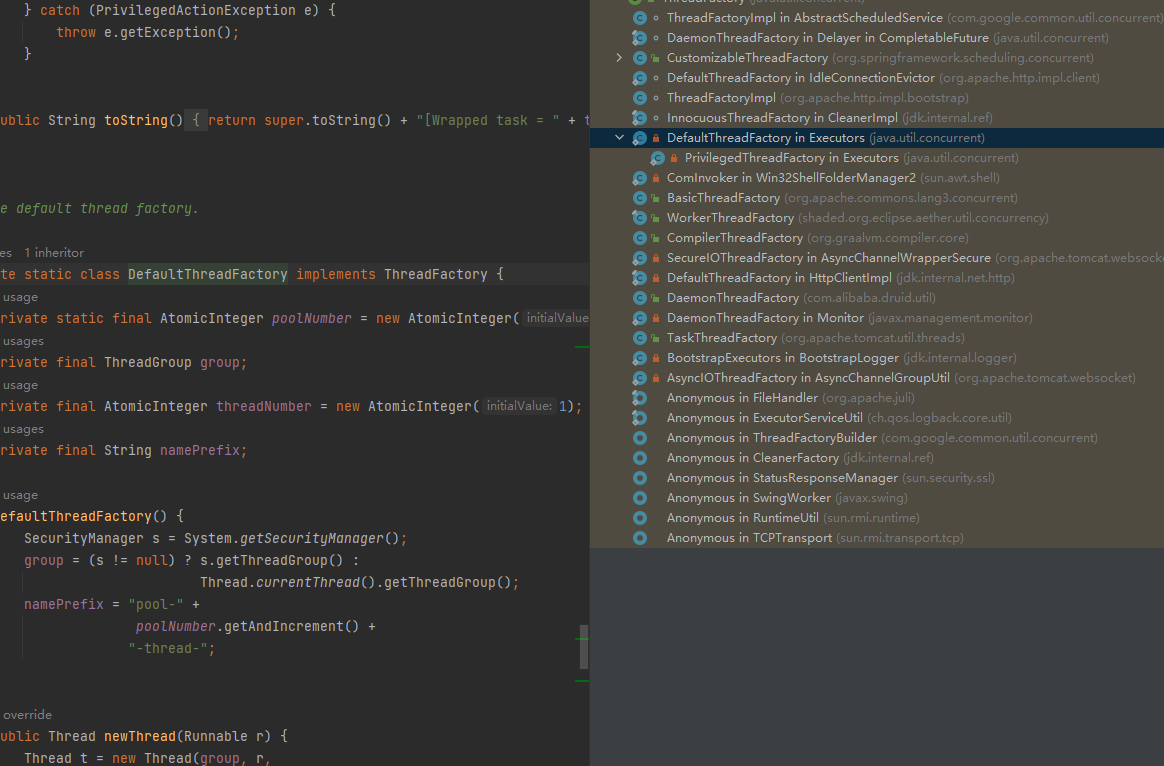
我们先看看ThreadFactory(接口)的继承关系,可以看到实现类很多,我们一般情况如果没有多任务的需求的话就使用defaultThreadFactory即可。
所以Guava就提供了这么一种链式编程方式(其实看官方注解可以发现是建造者),可以修改线程组命名,位于gcuc包中:
1 | import com.google.common.util.concurrent.ThreadFactoryBuilder; |
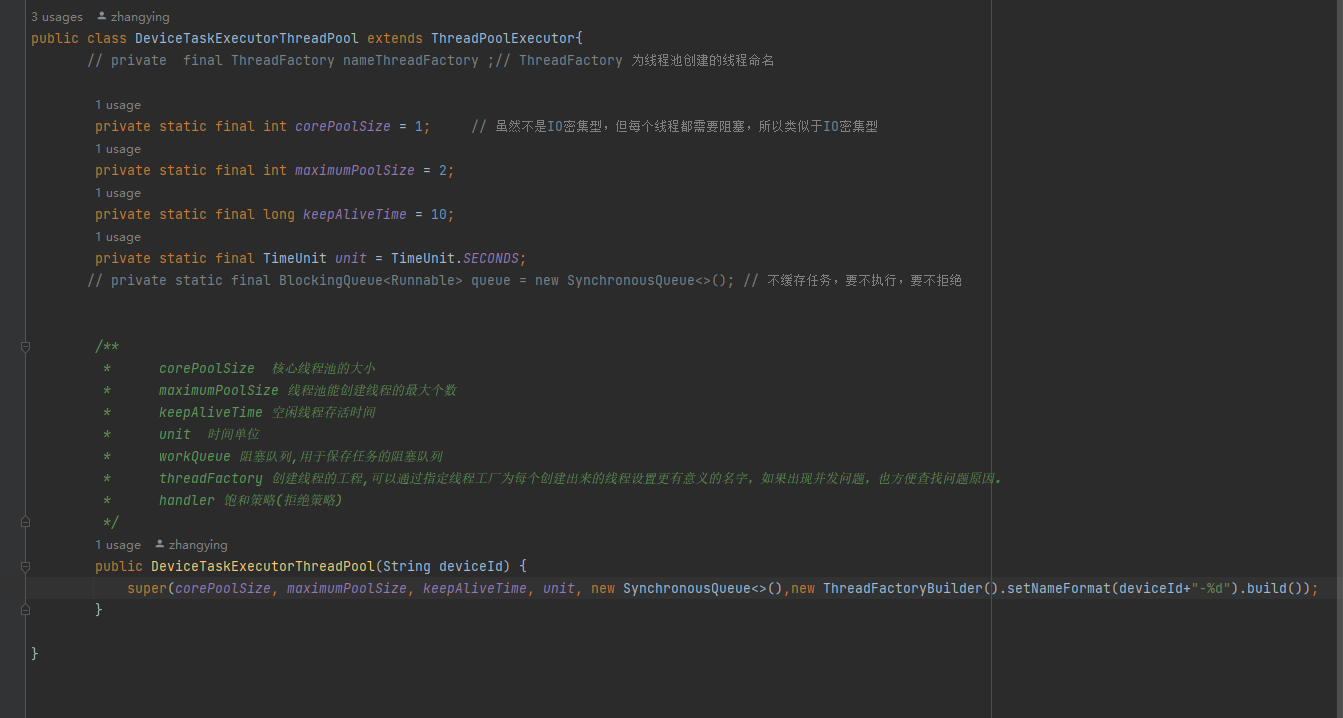
可以很清楚的看到我这里是新创建了一个线程池类,是为了解耦合,没有直接在业务实现类中new ThreadPoolExecutor,然后调用的super父类构造,下面解读下这个代码
1 | new ThreadFactoryBuilder().setNameFormat(deviceId+"-%d").build()); |
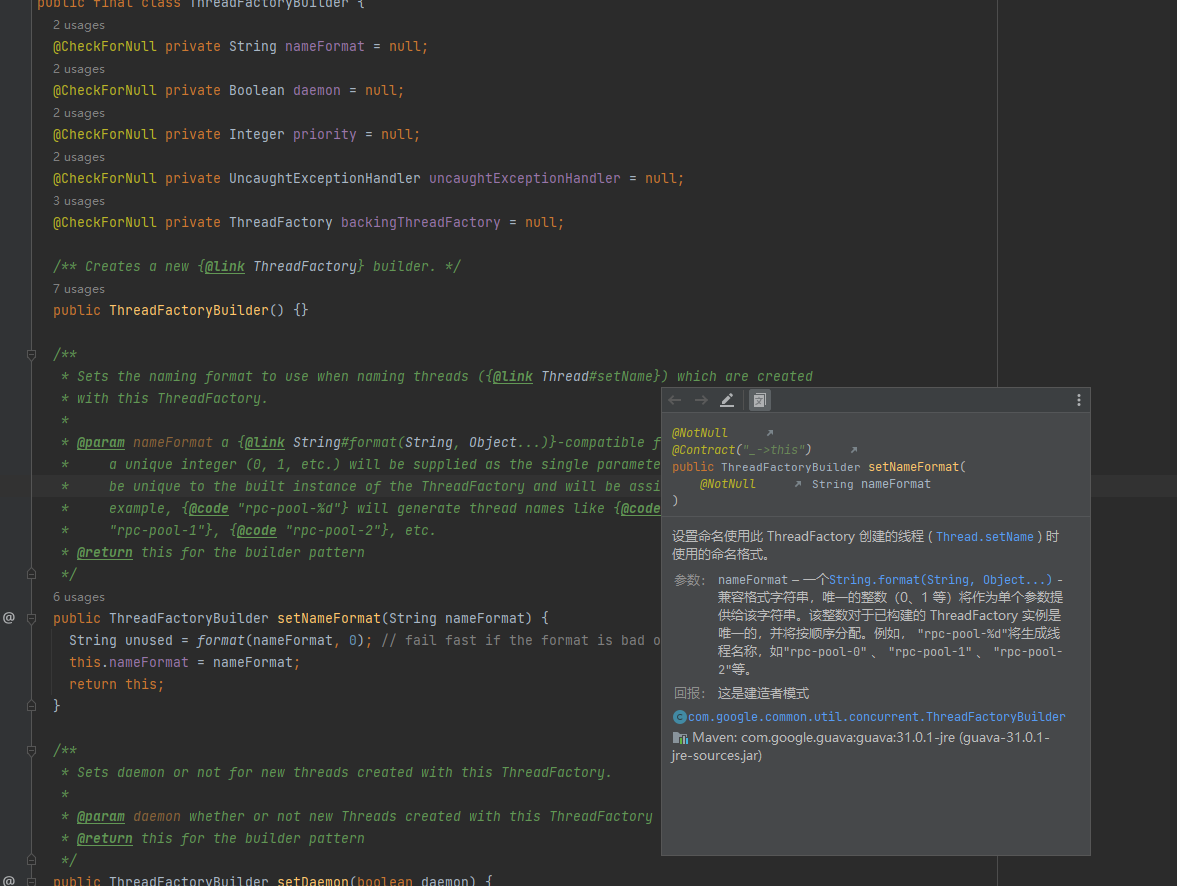
可以看到注解写的很清楚,某一任务的线程池的名称才是按照数字递增的,将不同池之间进行区分,
-%d代表从0开始递增。
线程池问题
首先说下运算类型:CPU密集型、IO密集型
都很好理解,前者是系统执行任务主要聚焦在CPU上,内存硬盘等硬件不是限制系统运行的瓶颈,内存等资源的占用率很低,而CPU常常处于100%,后者同理。
一般如何设置线程池大小(核心线程数)?N代表CPU的核心数,正常还是一个核心一个线程
为什么设置线程池大小,原因是为了提升CPU使用率,理想情况我们想让CPU为100%,不会浪费Cpu资源,所以我们才分了上面两种情况
对于计算密集型,系统任务主要都集中到运算上,所以CPU利用率很高,所以一般N+1即可,为什么不直接设置成N呢?
原因是计算密集型可能会因为某些原因暂停,比如页缺失,所以这个额外的线程会保证空出来的一个线程资源不会被浪费。比如复杂的算法
对于IO密集型,常常会发生IO阻塞,所以此时CPU处于闲置状态浪费资源,所以要更大的线程数
当然如果不是iO密集型,但是线程会常常阻塞,所以可以当作IO密集型来处理
如果是IO密集型,那么线程池大小是2N+1,当然2N也是可以的,应用场景大多是IO密集型的,比如文件传输、数据库交互、网络数据传输。
1 | 当然还存在混合型任务,这样的话一般就是多线程池,将任务的操作进行划分,分为上面两种,然后分别处理。 |
IO优化中,这样的估算公式可能更适合:
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CP U数目。
因为很显然:
(1)线程等待时间所占比例越高,需要越多线程。
(2)线程CPU时间所占比例越高,需要越少线程。
一个问题
1 | 高并发、任务执行时间短的业务怎样使用线程池?并发不高、任务执行时间长的业务怎样使用线程池?并发高、业务执行时间长的业务怎样使用线程池? |
你的项目中线程池主要用在这几个地方
1.下载app上,使用线程池下载,核心线程数为4,最大线程数8,线程工厂自己Builder
执行调用execute方法执行,这个方法在Executor顶层接口中定义,方法参数当然是线程体也就是Runnable,直接传入service方法到lambda中匿名Runable类作为参数即可。
2.执行任务上,前面说了通过各种任务封装生成任务执行对象,这个对象是Runnable类型,那么直接把这个任务扔到任务线程池即可,这个任务线程池使用的是SynchronousQueue
1 | 使用了多线程的好处就是不是单线程的等待代码执行了,而是将任务执行依赖于责任链的任务进度。比如线程分配了download任务,线程池去下载然后下载完之后,各自的下载线程通知Observer,然后Observer完成相对应onNext(); |
项目线程池执行流程:任务是运行态动态生成的,而我们的线程池的new是在bean的构造方法中执行的,也就是bean创建时就生成了线程池对象,我们后面直接接收到请求处理service扔进线程池就可以
能不能改成普通队列呢?
当然可以,因为多个任务是互不干扰的,所以当然可以使用其他队列,就比如LinkedBlockingQueue,关键是设置好它的参数这里用SynchronousQueue只是保证了最基础的不会溢出,可以按需求自己设置,这里使用core = 1,max=2设置的很小,就是因为再开发环境测试时可能CPU太高,所以下载就直接N,这边执行直接取的1,max = 2
SynchronousQueue
SynchronousQueue的目的就是保证“对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务”。联想一下线程池i执行流程,首先core = 1,任务进来直接执行,再进来进入到queue中,因为max = 2,所以直接创建一个但是限制为2,就是为了避免newCacheThreadPool的问题,所以才要规定max。
1 | 为什么newCacheThreadPool可以实现无限线程,原因是core=0,新来的任务直接进入queue,然后直接新建线程执行。 |
SynchronousQueue内部没有容器,一个生产线程,当它生产产品(即put的时候),如果当前没有人想要消费产品(即当前没有线程执行take),此生产线程必须阻塞,等待一个消费线程调用take操作,take操作将会唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递),这样的一个过程称为一次配对过程(当然也可以先take后put,原理是一样的)。
具体当有空闲线程了,此时队列中的任务是怎么提交给现成的呢?
这是ThreadPoolExecutor实现的,其实是调了非阻塞的offer,交给空闲线程,没有空闲就要新建。
其实线程池的参数的设置还和系统其他硬件资源,甚至是QPS都能扯上关系
QPS也就是每秒能够处理的请求数,计算时QPS=线程数*(每秒能执行的操作数)
假如一次请求执行的时间是100ms,那么单个请求QPS就是1000/100=10,所以如果线程数=10,那么总QPS=100
假如此时说规定DB最大QPS是20,那么线程数也就缩小到原来的一半,这样计算适用于QPS有限制的场景如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !