实现高性能、一致性、高可用
前端进行一次md5加密,传输过程中再进行一次加密,提高安全程度
利用逆向工程由数据库表和模板来生成对应的实体类、接口、实现类等等,需要的保留,不需要的在后续中删除
开发登陆功能是为了为后续的秒杀功能提供鉴权,只有用户才能进行秒杀
登陆页面中校验和前端的返回值不再使用return返回数据枚举或常量类,而是抛出异常来被ControllerAdvice捕获,进行统一的异常处理,为了程序的健壮性,减少service中的service校验代码,直接使用Valication框架,基本规则通过已定义的注解限定变量,自定义的校验规则使用自定义注解设定默认规则和@Constraint(validatedBy = {.class})来指定规则类来实现
Nginx 使用默认负载均衡策略(轮询),请求将会按照时间顺序逐一分发到后端应用上。
所以需要解决分布式Session问题(多个Tomcat用SpringSession或redis实现session的同步)
不再使用多个tomcat去存储session,而是使用一个独立的redis存储
秒杀相关问题
页面缓存:并发的问题主要存在于数据库,所以要尽量减少对数据库的访问,所以可以加缓存,除了页面缓存之外,还有对象缓存、URl缓存等等
页面不需要系统整个的来生成页面同时整个页面地传输,减少流量,改为从缓存中取html取页面,取不到页面(缓存过时间失效了)的话就在后端执行生成并保存到redis,一般对缓存设置一个失效时间,因为缓存也不是一直能用的,除非数据根本不会变,那样推荐直接页面静态化,URL静态化是指多页面情况下,比如通过id来确定访问某一个id的页面。一般适用于更改数据比较频繁的页面,所以失效时间不能太长。
页面静态化:通过直接访问纯HTml来减少对服务器的请求以及减少数据在网络中的传输,比如动态页面优化后,改用vue或其他的方式只传输页面中需要变化的数据部分,来实现前后端分离,这样还不能说是完全的页面静态化,完全的使用html才是页面静态化,一般静态化应用于更改很少的页面,当改变数据时的同时调用静态化。
秒杀存在的问题:超卖问题,一个用户在高并发请求下多次秒杀,库存减少数和订单生成数不一致
解决方法:
超卖:在减少库存的sql语句上同时判断库存是否为0,如果为0不满足sql条件,所以减库存sql不能被执行
库存减少数和订单生成数不一致:库存减少语句生成boolean值,true才能生成一条order
一个用户在高并发请求下多次秒杀:数据库表添加索引,就是分表,秒杀的订单和正常的订单是两张表,在数据库中建立用户id和商品id的唯一索引,防止用户插入重复的记录。
每次插入的时候,索引不能重复就不能插入,因为写了事务的注解 就会回滚。
还可以将订单插入到缓存中。
将数据库访问加入到redis中,继续优化:也并不是将所有请求都交给redis,而是设置队列依次执行,在用户端提供一个队列等待的友好提示,用队列解决高并发的问题
RabbitMQ四种交换机(六种模式):
生成一个Binding对象,采用哪种模式需要哪些就绑定哪些(quene,exchange等等)
simple简单模式:work quene,一个生产者对应多个消费者,但是一个消息只能有一个消费者
Fanout:广播模式也叫订阅者发布者模式,直接指定队列和交换机,不需要routingkey(路由键)
Direct:直连模式也叫rouing路由模式,在基本模式上加上routingkey来指定消息具体进入哪一个队列,queue由它的路由键来对应消息携带的路由key
Topic:主题模式,在路由key很多的情况下难以管理,所以在路由模式的基础上加入了通配符,通配符*代表以一个单词,#代表多个0个或多个单词(任意个)
Headers(用的少):头部交换机
RPC模式
在comfig中配置需要用的参数(queneName、交换机exchange、routingkey通配符策略等等)
JUC并发问题:
voliate:保证了可见性和有序性
涉及到指令重排问题,指令重排是CPU为了提高任务执行的速度,提高CPU的吞吐率而采用的一种流水线导致的,程序语句之间可能会发生重排(概率很低),重排在某些情况下会产生错误,比如在多线程的情况下执行对共享资源的操作,如果下面不会出错
1 | int i = 1; |
但是下面可能出错,即有可能下面的语句先执行,但是上面的i还没赋值
1 | int i = 1; |
所以关于指令重排的禁用就可以使用voliate,在共享变量声明时前面加上,以后每一次操作该变量都会按voliate规则:
对voliate变量的写指令后会加入写屏障,导致该语句和前面的所有语句都在写屏障中,屏障保证了其中的语句不会到屏障的外面,即到写语句的后面,所有对共享变量的改动都同步到主存中,而不是同步到缓存中
相对的在voliate变量的读指令前会加入读屏障,对变量的读取加载的都是写屏障中同步到主存中的最新数据,所以保证了可见性
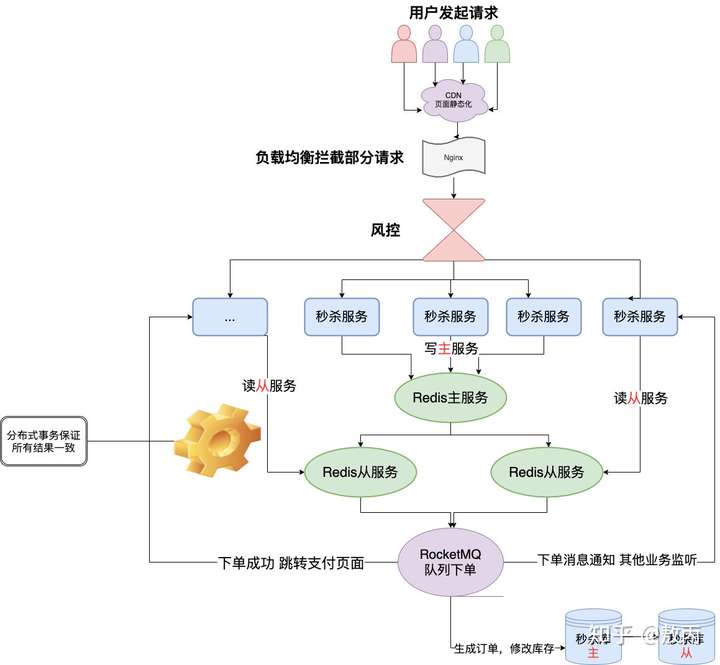
Redis设置主从架构以及进行读写分离,master进行秒杀的写操作,比如预减库存,订单计数等等,slave进行读操作,比如库存的判断以及订单是否存在,当然订单是否存在可以有也可以没有,最后数据库层面一定会进行去重。
需经过队列之后的数据库也一定是主从架构的,主库进行数据的修改,从库进行同步。
秒杀的入口:
使用Nignx进行请求拦截,比如10W请求只放进来1W个,因为秒杀对于用户来说原本就是黑盒操作的,不像转盘一样是可见的,即使是转盘请求也可以处理完之后在前端展示相对应的转盘动画,因为动画的时长一般是远大于请求响应的时长的。
请求进来了1W,还是有很多的恶意用户的,如何去拦截呢?一般企业都会有相对应的风控措施,对于风险账号进行限制或者对请求方进行判断是否是机器操作,但是有的专业薅羊毛团队会使用群控的方式,使用真实的用户和设备进行访问,或者使用selenium自动化测试进行频繁访问,我么可以统计用户实用信息,维护一个打分系统进行打分,尽量选择分数高的用户完成秒杀,因为都是黑盒操作的。
另外其实号也是可以养的,但一般基于某些业务场景,比如支付宝,账号的成本是很大的,所以一版本是特别担心,对于重要场景的风控也是很严格的。
后端:
后端的各个服务的职责一定是单一的,什么服务做什么工作,主从工作也要进行区分。
四大战法: 集群+主从+读写+Redis哨兵
对于服务的保护其实四大战法就起到了高可用的作用,下面也能对服务进行保护:
限流&降级&熔断&隔离
分布式事务
这为啥我不放在后端而放到最后来讲呢?
因为上面的任何一步都是可能出错的,而且我们是在不同的服务里面出错的,那就涉及分布式事务了,但是分布式事务大家想的是一定要成功什么的那就不对了,还是那句话,几个请求丢了就丢了,要保证时效和服务的可用可靠。
所以TCC和最终一致性其实不是很适合,TCC开发成本很大,所有接口都要写三次,因为涉及TCC的三个阶段。
最终一致性基本上都是靠轮训的操作去保证一个操作一定成功,那时效性就大打折扣了。
大家觉得不那么可靠的两段式(2PC)和三段式(3PC)就派上用场了,他们不一定能保证数据最终一致,但是效率上还算ok。
项目有什么不足的地方:
没有使用Nignx负载均衡策略,Nignx可以拦截一部分请求,在Nignx之前会有CDn进行静态化,其实和我们在Freemarker或者Redis进行存储数据是一样的,都是预先存储了静态数据。
什么是CDN:
CDN是的数据是分布式地存在了服务器上(内容分发网络),内容分发也就是预先将资源存储在服务器节点上,根据请求的位置,选择最近的服务器返回请求,将会大大地提升请求速度,如果只是在本地服务器上进行持久化或者在Redis上存储数据,那么网络的延迟受传输的影响很大,不如就近分发。当然CDN除了提升速度外,大大减少了对核心服务的无用请求,可以将核心服务器的有限的计算资源利用到最核心的业务上。
CDN的加速资源和域名是绑定的,访问域名时,会通过DNS查找最近的CDN节点,找到其IP地址,注意CDN节点是分为中心节点和边缘节点的,一般进行具体分发的都是边缘节点,通过IP访问CDN资源时,如果这个边缘没有,那么该节点会到源站(即域名站点)进行请求资源保存,下一次就能直接获取到第一次保存好的数据了。
什么是负载均衡?
负载均衡实际上就是将大量请求进行分布式处理的策略,它是一种调度策略。
什么是正向代理?
客户端非常明确要访问的服务器ip地址,它代理客户端,替客户端发出请求。比如:科学上网,爬虫。
什么是反向代理?
并不是说请求反向,而是说随着用户请求的增长,服务器必须多台分布式进行处理,来自不同client的请求还是都发到代理服务器上,由代理服务器决定分发到哪里的具体服务器上,客户端并不知道是哪个服务器IP处理了自己的请求,Nignx处理完之后再将响应回传。反向代理代理的是服务器端。
反向代理需要考虑的问题是,如何进行均衡分工,控制流量,避免出现局部节点负载过大的问题。通俗的讲,就是如何为每台服务器合理的分配请求,使其整体具有更高的工作效率和资源利用率。
Nginx 是什么?
Nginx 作为一个基于 C 实现的高性能 Web 服务器,它是一个软件,可以通过系列算法解决上述的负载均衡问题。并且由于它具有高并发、高可靠性、高扩展性、开源等特点,成为开发人员常用的反向代理工具
负载均衡常用算法
轮询 (round-robin)
轮询为负载均衡中较为基础也较为简单的算法,它不需要配置额外参数。假设配置文件中共有 台服务器,该算法遍历服务器节点列表,并按节点次序每轮选择一台服务器处理请求。当所有节点均被调用过一次后,该算法将从第一个节点开始重新一轮遍历。特点:由于该算法中每个请求按时间顺序逐一分配到不同的服务器处理,因此适用于服务器性能相近的集群情况,其中每个服务器承载相同的负载。但对于服务器性能不同的集群而言,该算法容易引发资源分配不合理等问题。
加权轮询
为了避免普通轮询带来的弊端,加权轮询应运而生。在加权轮询中,每个服务器会有各自的 weight。一般情况下,weight 的值越大意味着该服务器的性能越好,可以承载更多的请求。该算法中,客户端的请求按权值比例分配,当一个请求到达时,优先为其分配权值最大的服务器。特点:加权轮询可以应用于服务器性能不等的集群中,使资源分配更加合理化。
IP 哈希(IP hash)
ip_hash 依据发出请求的客户端 IP 的 hash 值来分配服务器,该算法可以保证同 IP 发出的请求映射到同一服务器,或者具有相同 hash 值的不同 IP 映射到同一服务器。特点:该算法在一定程度上解决了集群部署环境下 Session 不共享的问题。
其他算法
总结
Nginx 作为一款优秀的反向代理服务器,可以通过不同的负载均衡算法来解决请求量过大情况下的服务器资源分配问题。
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !